一个比较有潜力的 Agent 项目 —— Agent-Sentinel
2026 年 6 月 15 日
Agent-Sentinel 是一个开源的 Agent 项目,旨在解决工程师在多平台、多渠道、高频切换下处理告警的痛点。它通过飞书回调拦截报错,并行抓取日志、指标、Trace 等多源数据,利用 LangGraph 编排节点,将候选根因反馈给工程师做最终决策。实测根因定位准确率超过 90%,并配套可观测平台监控缓存、Token 用量和延迟。未来计划接入更多办公软件和云厂商,构建根因知识库并实现自动化工单,以缩短 MTTR。
最近参与了一个开源的 Agent 项目,特开一篇文章来介绍这项目在未来的价值方向
先贴一下这个项目的开源地址
先来说明一个痛点。
在我们日常的开发流程中,工程师很大一部分精力其实并不是在写新功能,而是在”救火”——处理各种报错信息。监控平台、日志平台、各种云服务,错误来源被分散在十几个系统里。随着技术债越积越深,我们日常的开发任务反而变得不那么重要,真正重要的是<在有限的时间里>,如何快速定位线上问题、解决疑难杂症。
我之前就遇到这样一个真实的场景: 为了排查一段 SQL 的数据问题,我不得不去翻日志。结果发现其中一个下游子链路的 SQL, where 后面竟拼接了几千个参数,只是为了判断查询条件中是否带有某个 ID。有点地狱了

现在主流的监控平台确实都支持查询语法,比如 Datadog 的 service:xxx AND error:xxx、SLS 的全文索引、Skywalking 的 TraceId 关联。但编写这些查询语法本身,就会浪费掉不少时间——单次大概在几十秒不等。如果要同时在性能监控平台、日志平台、公司内部子系统平台之间来回切换,光是查询条件的编写,可能就是几分钟起步。
(那种在十几个 Tab 之间反复横跳,一边查 traceid、一边翻日志、一边看指标的体验,相信做过 SRE 的人都懂 hhh。)
现有模块一览
| 模块 | 选型 | 理由 |
|---|---|---|
| Agent 编排 | LangGraph | 节点可观测、扩展性强、支持并行分支 |
| 办公接入 | 飞书 OpenAPI | 团队标配,回调机制成熟 |
| 云服务适配 | 各厂商 SDK | 配置即用,降低接入成本 |
| 缓存 | Redis | 语义向量 + 精确 key 双策略 |
| 监控 | Prometheus + Grafana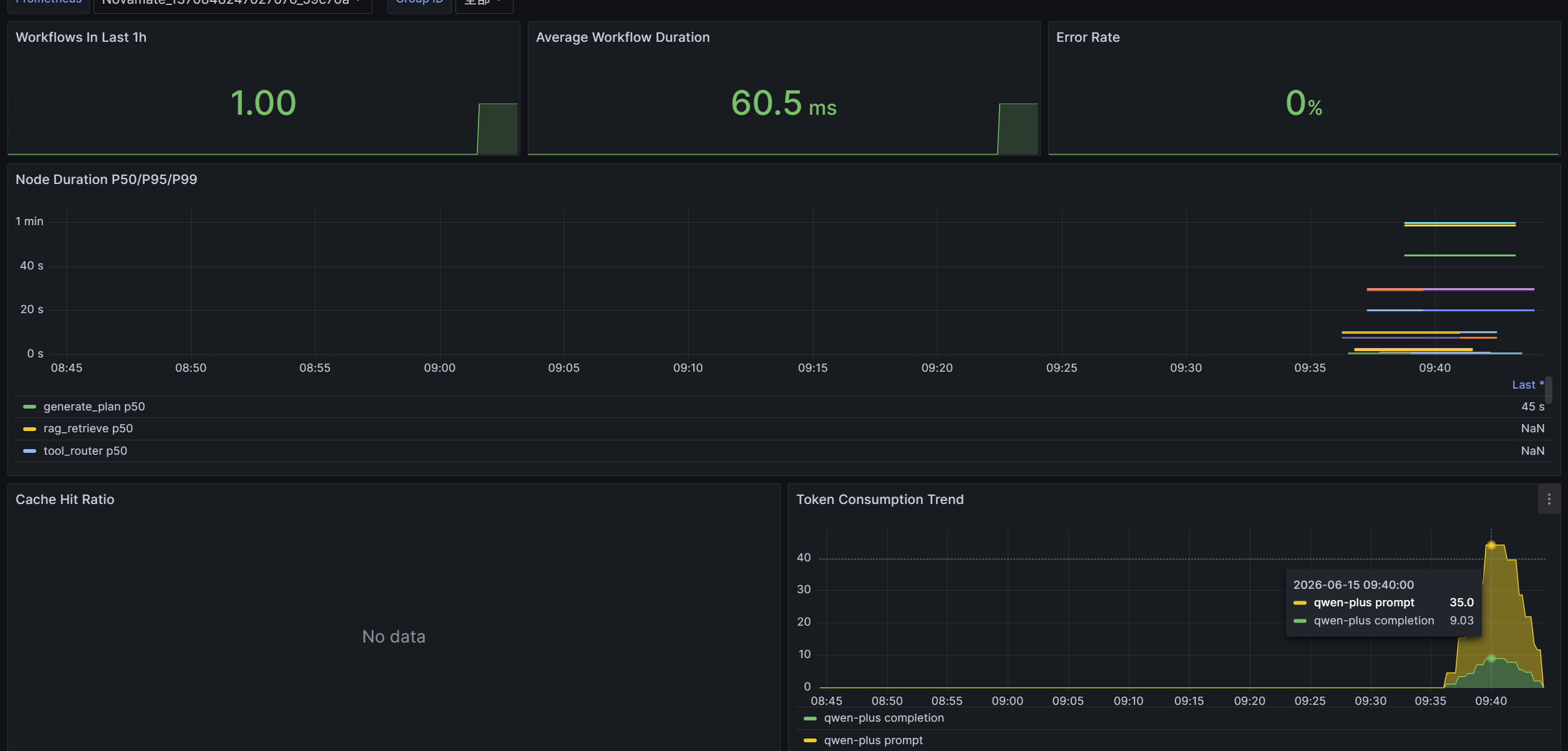 | 与公司现有可观测体系打通,可监控缓存命中率、token输入输出的用量 |
| 部署 | Docker | 方便使用 |
痛点的本质: 多平台 × 多渠道 × 高频切换
把这个痛点再抽象一层,其实就是三个关键词:多平台、多渠道、高频切换。
- 多平台<性能监控>、日志、业务监控、APM、Trace,每个平台都有自己的一套查询 DSL;
- 多渠道<告警来自飞书>、邮件、短信、电话、值班机器人;
- 高频切换<一次故障处理>,要在 5~10 个平台之间反复跳转。
人肉去拼这些查询条件,既是低效的,也是容易出错的。漏一个条件、拼错一个字段,排查方向就跑偏了。
我们的解法
所以基于这个痛点, 我们做了这样一个 Agent 项目——Agent-Sentinel(哨兵),核心目标是<把工程师从>”机械的信息检索”中解放出来,让 Agent 去做那些重复、低价值、但又必须做的工作。
它主要解决了以下几件事:
- 主流办公软件接入<目前已支持飞书的告警回调>,可以无侵入地拦截生产环境的报错信息;
- 多云 SDK 适配<支持接入各大云服务的> SDK,配置简单,即可读取各大云服务的资质与参数信息;
- 精细化查询<内部封装了与各大平台适配的查询> SQL 提示词,能够在特定时间段、特定服务链路中精准查询;
- 综合决策<通过飞书回调拦截报错后>,综合性地抓取数据、关联上下文,最后将可能的原因整理反馈到群里;
- 人机协同<最终的判断依然交给工程师>,Agent 负责的是”信息聚合 + 候选假设”。
关键架构设计: 为什么选 LangGraph
技术栈上,我们选择的是 LangGraph 来做节点编排。这个选择其实是经过权衡的。
最初我们也考虑过直接用 LangChain 的 Chain 模式,或者干脆写一个大的 ReAct Agent。但很快就遇到了几个问题:
- 上下文窗口吃紧<一个完整的故障现场>,涉及 trace、日志、指标、配置变更,信息量极大,直接塞进 Prompt 会让 LLM “失忆”;
- 多步骤不可控
的循环深度不可预测,容易陷入”查询 → 没结果 → 换关键词 → 再查询”的死循环; - 扩展性差<业务在演化>,需求在变化。如果硬编码调用逻辑,后续改造成本会非常高。
而 LangGraph 的 Stateful Graph 模型天然适合这个场景:
- 每个节点是一个独立的能力(查日志、查指标、查 trace、生成假设、汇总报告),节点之间通过共享 State 传递数据;
- 可以显式地控制流转路径,比如”如果某个节点返回空,就走兜底分支”;
- 新增能力只需要加一个节点 + 一条边,不需要改既有逻辑。
下面是一个简化版的图结构示意:
# 伪代码:Agent-Sentinel 的核心图结构
from langgraph.graph import StateGraph
workflow = StateGraph(AgentState)
# 1. 解析告警
workflow.add_node("parse_alert", parse_feishu_alert)
# 2. 并行抓取多源数据
workflow.add_node("fetch_logs", fetch_sls_logs) # SLS 日志
workflow.add_node("fetch_metrics", fetch_dd_metrics) # Datadog 指标
workflow.add_node("fetch_trace", fetch_skywalking) # SkyWalking trace
workflow.add_node("fetch_config", fetch_recent_changes) # 最近配置变更
# 3. 多路并发后汇总
workflow.add_node("aggregate", aggregate_context)
workflow.add_node("hypothesize", llm_make_hypothesis)
workflow.add_node("notify", send_to_feishu)
# 边:解析 → 并行抓取 → 汇总 → 假设 → 通知
workflow.add_edge("parse_alert", "fetch_logs")
workflow.add_edge("parse_alert", "fetch_metrics")
workflow.add_edge("parse_alert", "fetch_trace")
workflow.add_edge("parse_alert", "fetch_config")
workflow.add_edge("fetch_logs", "aggregate")
workflow.add_edge("fetch_metrics", "aggregate")
workflow.add_edge("fetch_trace", "aggregate")
workflow.add_edge("fetch_config", "aggregate")
workflow.add_edge("aggregate", "hypothesize")
workflow.add_edge("hypothesize", "notify")
workflow.set_entry_point("parse_alert")
app = workflow.compile()这里有个细节——fetch_logs / fetch_metrics / fetch_trace / fetch_config 这四个节点是 并行执行 的(通过 LangGraph 的 fan-out)。在生产环境的实测里,这一波并行抓取,比原来的串行调用快了将近 4 倍。
后续如果想扩展(比如把报错信息入库、做离线的根因分析、对检索信息做即时反馈),都只需要新增节点、修改图的边配置,完全不需要动核心逻辑。
准确率与可观测性
光跑通还不够,我们更关心的是 稳不稳。
在我们团队长时间的测试下,Agent-Sentinel 的根因定位准确率能够保持在 90% 以上。这个数字其实有点超出我们的预期——一开始我们只敢估计 60~70%。后来分析下来,准确率高的核心原因有两个:
- 上下文足够丰富<多源数据>(日志 + 指标 + trace + 配置变更)同时摆在 LLM 面前,误判率显著下降;
- 提示词工程做得到位<每个数据源的查询都有专门优化的> Prompt,把”原始数据 → 结构化结论”这一步做得比较扎实。
但 90% 不是 100%,所以我们坚持一个原则:Agent 只给候选,不做最终决策。最终拍板,还是工程师。
另外,我们也为这套系统配上了对应的 可观测性平台,监控以下几项关键指标:
- 缓存命中率<对于一些高频查询>(比如同一个服务的常见错误),我们做了语义缓存,避免重复打 LLM;
- Token 输入与输出<精确到每一次> LLM 调用的 prompt / completion token,方便算账;
- 节点耗时
每个节点的执行时间都有埋点,可以快速定位瓶颈; - 飞书回调延迟<从告警触发到消息推回群里的端到端延迟>。
可观测性这件事,我们认为是 Agent 项目能不能落地的关键。一个黑盒 Agent,业务团队是不敢用的。
这件事的未来价值
写到这里,可能有人会问<大模型这么火>,这件事到底有没有未来?
我的看法是:非常有。
回到本质,Agent 在生产环境的价值,从来不是”替代人”,而是把工程师从重复劳动里解放出来。SRE 同学最值钱的时间,应该花在架构优化、根因复盘、防患于未然,而不是拼查询条件。
而 Agent-Sentinel 切中的,恰好是几乎所有有一定规模的技术团队都会遇到的痛点——多平台、多渠道、高频切换。它不是一个”花架子 Agent”,而是一个 真正能跑在生产环境、能稳定输出价值 的工程化 Agent。
未来我们计划在以下几个方向继续演进:
- 接入更多办公软件<企微>、钉钉、Slack;
- 支持更多云厂商<目前主要是阿里云> + Datadog,后续会扩展到 AWS、Azure;
- 根因知识库<把历史上确认过的根因沉淀成> RAG 知识库,让 Agent “越用越聪明”;
- 自动化工单<从>”给候选”升级到”开自动化工单”,进一步缩短 MTTR。
正在加载评论...